Uploading Textures to GPU - The Good Way
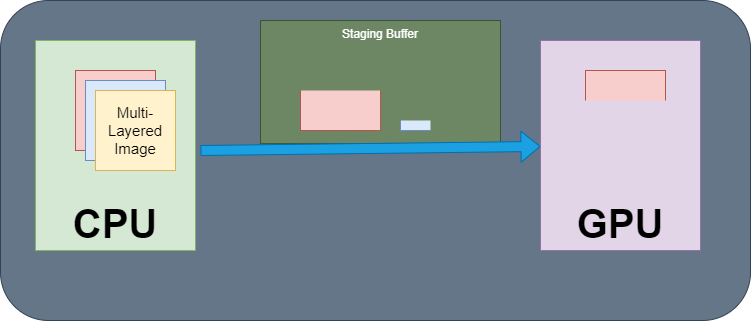
In this short blog post, I will explain the new utility I added to our open-source Nabla Framework, which is a tool used to upload a texture asset to the GPU over a staging buffer.
This tool can upload your texture in batches, meaning when there is not enough “transfer” memory we submit every single block of texture we can and pick up where we left off after the upload to GPU is finished.
Nabla Framework has a very similar front-end as Vulkan, and actually has Vulkan as one of it’s backends! so expect a lot a vulkan literature from me here.
Additionally I use “copy” and “transfer” interchangeably.
Before going into this blog, It’s best if you have an understanding how “Modern” Rendering APIs work with memory and submission of work to GPU.
And also I should note that the article focuses on transferring very large resources in possibly unsupported formats across a fixed size reusable multithreaded staging buffer. Its not a benchmark or analysis of best heap and memory type for a staging buffer; here its irrelevant and triviality what buffers we create and where with which memory flags, as its completely user configurable.
Let’s get started.
Uploading Textures - The Bad/Tutorial Way
Here is a high level descriptions on the simplest approach to transferring your textures to the GPU:
- Image is loaded into CPU Memory
- Create a CPU-mappable buffer + memory for it, sometimes referred to as
StagingBufferorStagingMemorywith the size of the loaded image (in vulkan terms isHOST_VISIBLEand sometimes additionallyDEVICE_LOCAL) - Record a copy command from a Buffer to GPU-side Image into a commandbuffer
- Submit that command buffer to a “Transfer” capable Queue
- Wait for the submission to complete using a fence or semaphore indicating the transfer is done!
The problem with this approach is allocating gpu memory each time you want to upload a texture, and this is not good. Even if you’re using tools such as VulkanMemoryAllocator that handles your allocations via pools or custom allocators, you’d still run into problems.
What if there is not enough “Staging” memory available at the moment for you to allocate? Due to it being currently in use by other processes or threads. or even if the GPU has not enough “Staging” memory available for your big MEGA texture.
The most important thing to tackle is that on Dedicated GPUs the amount of HOST_VISIBLE and DEVICE_LOCAL memory used to be very limited, for example 256 MB, and that’s what you want to use for staging, so the CPU is already writing to VRAM and GPU doesn’t need to pull across PCIE. Also we want predictable memory usage, you don’t want 1GB memory usage spikes.
# Uploading Textures - The Good Way
-
Our tool, unlike the simple method, creates a single host-mappable buffer (default 64MB) in DEVICE_LOCAL memory if possible and creates a “range allocator” over it or as we like to call it
GeneralpurposeAddressAllocator, which basically allocates you an offset+size into the buffer. The size of this buffer may be much more than the texture you want to upload or much less, that doesn’t matter to our tool. -
try to allocate
min(neededSizeToFinishTransferInOneSubmit, maximumPossibleAllocationSize)from the range allocator and get an address into our buffer - Record the copy commands in this order
- Try to upload as much arrayLayers as possible
- If failed try to upload as much slices/depth as possible (makes sense for 3D textures)
- If failed try to upload as much rows as possible
- If failed try to upload as much blocks as possible
- Repeat until we run out of staging memory
- When you run out memory, submit everything to the queue and repeat again until the whole region is transferred.
We should always assume there may not be enough memory to do the whole copy/transfer in one submission that means we may need to submit every (copy) command we’ve recorded so far into the commandbuffers and resume our work; This means command buffers need to be submitted to the queue once the allocation fails (not enough memory)
This brought certain implementation and interface challenges mentioned in the next parts in more detail.
Some Cool Additions and Features
1. Format Promotion
There is a lot constraints/limits imposed by your PhysicalDevice/GPU which you should look out for in your applications; One of these constraints include the formats and other properties you can create your images with.
Your loaded assets may not be in the format you can use on the GPU, for example 24-bit JPEGs without an alpha channel. A simple solution is to convert your assets in your build pipeline.
If your framework like Nabla, has the CPU functions to decode and encode pixels values between every single one of the 150+ common VkFormats, you can convert the texture at runtime on the CPU. The naive approach would require allocating CPU-side memory for a third copy of your already MEGA texture, possibly an even larger copy as you can’t convert the format to anything with a smaller bit-depth/precision.
Our solution streaming converts the format of the Texel Blocks WHILE copying them to the Staging memory, and there is no need for additional allocations! So for example you could have R8G8B8 asset and upload that to a B8G8R8A8 VkImage, or even decode from an unsupported block compressed format 🙂
This is all implemented in the framework of our Asset namespace where a mutable ICPU counterpart exists for every IGPU object (VkObject in the Vulkan backend). An ICPUImage is simply a recipe for creating VkImage and filling its contents with copies of regions from ICPUBuffer (which is a recipe for creating a filled VkBuffer).
Nabla possesses a number of Image Filters which operate on ICPUImages, including but not limited to:
- Copy
- ConvertAndSwizzle (with optional and custom dithering, default is Tileable 2D Blue Noise)
- Convolution (with Polyphase LUT optimization)
The way that this streaming convert works, is that our Utility creates an ICPUImage whose regions are backed by an CCustomAllocatorCPUBuffer<core::null_allocator> which itself is just a way to view any external void* as an ICPUBuffer, in this case the Mapped GPU Staging Buffer memory itself.
Later we just invoke the Convert or Copy Image Filter using this temporary image as the output.
Our framework supports all kind of abuse like that, for example you can masquerade a pointer from a memory mapped system::IFile as an asset:ICPUBuffer and a mapped video::IGPUBuffer (VkBuffer) as a system::IFile.
2. Taking Advantage of Physical Device Information
We take advantage of optimalBufferCopyRowPitchAlignment and optimalBufferCopyOffsetAlignment. (more details here)
Also noting that this tool is very Vulkan conformant and considers minImageTransferGranularity of the Queue you’re using for your command submission along with nonCoherentAtomSize if the staging buffer is not Coherent (needs manual cash flush/invalidate)
3. Our StreamingBuffer is Async
That means you can submit texture transfers in multiple threads and the allocation in the range allocator will be available/freed once the submission fence/semaphore has been hit, indicating the GPU is done with the transfer
Implementation Details (for curious minds)
One of the core parts of this tool is ImageRegionIterator that acts as an iterator over the region intended for transfer, based on availableMemory. you can think of it as a state to be resumed later.
You can see interface here and implementation here.
The main challenges with this tool was that it needed to do in between submits, and in a low-level framework such as Nabla might come out as quite unpleasant, because:
- We don’t want to create command buffers + fence each time an upload is requested
- Ideally, We want the user to give us a command buffer to record copy command into and then let them submit themselves
- We want the user to be able to take advantage of certain synchronization features:
- be able to wait for semaphores before copy starts
- be able to signal certain semaphores after the copy finished
- be able to signal a fence when the copy is finished.
We need to be careful here, for the in-between submits, we shouldn’t signal the semaphores, the signal should only happen for the last batch of transfers.
Additionally, after an in-between submit has happened, we should nullify waitSemaphores of the submit user wants to do. because the wait has happened already (we ran out memory while transferring the image and we had to submit, no other way).
Here is the final interface we decided to go with that includes additional comments and notes above the function.
We also have the exact system in place for uploading/downloading buffers to/from GPU :)
Q&A
You can reach us and ask more about Nabla and this tool in our discord channel